수업내용/SQL
[2022.10.21.금] 서브쿼리
주니어주니
2022. 10. 21. 15:11
1-1. 서브쿼리
- 메인 쿼리 내부에 정의된 쿼리
- 다른 select 문의 내부에 정의된 select문을 서브쿼리라고 한다.
- 서브쿼리를 포함시킬 수 있는 곳
- where 절
- having 절
- from 절 (인라인뷰라고도 부른다)
- where, having절에서 조건으로 활용 -> 서브쿼리
from절에서 가상의 테이블로 활용 -> 인라인뷰 - 서브쿼리 형식
select column, column
from table
where column 연산자 (select column
from table)
- 서브쿼리의 특징
- 서브쿼리는 한번만 실행된다.
- 서브쿼리는 메인쿼리보다 먼저 실행된다.
- 서브쿼리의 실행결과는 메인쿼리의 조건식에서 사용된다.
- 조건식에서 비교값으로 사용되는 값이 쿼리의 실행결과로만 획득할 수 있을 때, 그 비교값을 조회하는 쿼리가 서브쿼리다.
- 서브쿼리 사용시 주의점
- 서브쿼리는 반드시 괄호로 묶어야 한다.
- 조건식의 오른쪽에 서브쿼리를 위치시키면 가독성이 높아진다.
- 서브쿼리의 실행결과가 단일행인지, 다중행인지에 따라 적절한 연산자를 사용해야 한다.
-- 서브쿼리를 사용하지 않고 전체 직원의 평균급여보다 급여를 많이 받는 직원의 아이디, 이름, 급여 조회하기
-- 1. 전체 직원의 평균급여를 조회한다.
select avg(salary)
from employees;
-- 2. 조회된 평균급여보다 급여를 많이 받은 직원을 조회한다.
select employee_id, first_name, salary
from employees
where salary > 6485.1962;
-- 서브쿼리를 사용해서 전체 직원의 평균급여보다 급여를 많이 받는 직원의 아이디, 이름, 급여 조회하기
select employee_id, first_name, salary
from employees
where salary > (select avg(salary)
from employees);
1-2. 서브쿼리의 종류
1) 단일행 서브쿼리
- 서브쿼리의 실행결과로 한 행만 반환된다. ( 1행 1열 = 서브쿼리의 실행결과가 1개 )
- 단일행 비교 연산자
- =, >, >=, <, <=, <>,
in을 적어도 됨(서브쿼리의 결과값이 단일행인지 다중행인지 확신할 수 없으니까 in으로 적어라)
- =, >, >=, <, <=, <>,
-- 'Neena'와 같은 부서에서 근무하는 직원의 아이디, 이름 조회하기
-- neena가 근무하는 부서가 1개니까 단일행 서브쿼리
select employee_id, first_name
from employees
where department_id = (select department_id
from employees
where first_name = 'Neena');

-- 전체 직원 중 최저 급여를 받는 직원의 아이디, 이름, 급여 조회하기
-- 여러명이어도 최저값이 1개니까, 테이블전체를 하나의 집합으로 보니까 서브쿼리의 결과값이 1개인거임
select employee_id, first_name, salary
from employees
where salary = (select min(salary)
from employees);

-- 'Neena'가 입사한 해에 입사한 직원 중에서, 전체 직원의 평균급여보다 급여를 적게 받는 직원의 아이디, 이름, 입사일, 급여 조회하기
-- 서브쿼리가 여러개 있을 수 있음 (단일행) 서브쿼리의 결과값이 하나
select employee_id, first_name, hire_date, salary
from employees
where to_char(hire_date, 'yyyy') = (select to_char(hire_date, 'yyyy')
from employees
where first_name = 'Neena')
and salary < (select avg(salary)
from employees);
2) 다중행 서브쿼리
- 서브쿼리의 실행결과로 여러 행이 반환된다. ( 서브쿼리의 실행결과가 여러 개 )
- 다중행 비교 연산자
- in, any, all
in : equal 비교
>all : 서브쿼리의 모든 조회결과보다 큰 값
>any : 서브쿼리의 조회결과보다 하나라도 큰 갓
- in, any, all
-- 직종 변경 이력이 있는 직원의 아이디, 이름, 현재 직종 조회하기
-- 서브쿼리의 결과값이 여러 행
select employee_id, first_name, job_id
from employees
where employee_id in (select distinct employee_id
from job_history);

-- 직종 변경 이력이 없는 직원의 아이디, 이름 현재 직종 조회하기
select employee_id, first_name, job_id
from employees
where employee_id not in (select distinct employee_id
from job_history);

-- 'Seattle'에서 근무중인 직원의 아이디, 이름 조회하기
-- 1. 'seattle'의 소재지 아이디 조회
-- 2. 해당 소재지 아이디에 위치하는 부서의 아이디 조회
-- 3. 해당 부서에 근무중인 직원 조회
select employee_id, first_name, job_id
from employees
where department_id in ( select department_id -- 다중행 서브쿼리
from departments
where location_id in (select location_id -- 단일행 서브쿼리 (in도 가능)
from locations
where city = 'Seattle') );
-- 'Seattle'에서 근무중인 직원의 아이디, 이름 조회하기
-- 서브쿼리로 조회가능한 내용을 join으로 구현해보기
select e.employee_id, e.first_name, e.job_id
from employees e, departments d, locations l
where l.city = 'Seattle'
and l.location_id = d.location_id
and d.department_id = e.department_id;

-- 80번 부서에 소속된 직원의 급여보다 급여를 많이 받는 직원의 아이디, 이름, 급여 조회하기
select employee_id, first_name, salary
from employees
where salary > all (select salary -- > all : 모든 값보다 큰 값 (최대급여보다 큰값)
from employees -- where salary > all (select salary ...) == where salary > (select max(salary) ...)
where department_id = 80)
and department_id != 80;
select employee_id, first_name, salary
from employees
where salary > any (select salary -- > any : 하나라도 큰 값 (최소급여보다 큰값)
from employees -- where salary > any (select salary ...) == where salary > (select min(salary) ...)
where department_id = 80)
and department_id <> 80;

3) 다중열 서브쿼리
- 두 개 이상의 컬럼값이 조회조건으로 반환되는 서브쿼리다.
-- 다중열 서브쿼리를 사용하지 않고, 145번 직원과 같은 부서에서 일하고, 같은 해에 입사한 직원의 아이디, 이름, 입사일 조회하기
select employee_id, first_name, hire_date
from employees
where department_id = (select department_id
from employees
where employee_id = 145)
and to_char(hire_date, 'yyyy') = (select to_char(hire_date, 'yyyy')
from employees
where employee_id = 145);
-- 다중열 서브쿼리를 사용해서, 145번 직원과 같은 부서에서 일하고, 같은 해에 입사한 직원의 아이디, 이름, 입사일 조회하기
select employee_id, first_name, hire_date
from employees
where (department_id, to_char(hire_date, 'yyyy')) in (select department_id, to_char(hire_date, 'yyyy')
from employees
where employee_id = 145);
-- 부서별 최저급여를 조회했을 때, 각 부서에서 최저급여를 받는 직원의 아이디, 이름, 급여, 부서아이디 조회하기 (다중행, 다중열)
select department_id, employee_id, first_name, salary
from employees
where (department_id, salary) in (select department_id, min(salary)
from employees
where department_id is not null
group by department_id)
order by department_id asc;

4) having절에서 서브쿼리 사용하기
- group by 절을 사용해서 그룹화하고 그룹함수를 실행한 결과를 필터링하는 having 절에도 서브쿼리를 사용할 수 있다.
-- 부서별 사원수를 조회했을 때 사원수가 가장 많은 부서의 아이디와 사원수 조회하기
select department_id, count(*)
from employees
where department_id is not null
group by department_id
having count(*) >= (select max(count(*)) -- 단일행 비교를 해야하니까 서브쿼리에 discount도 들어가면 안됨 max결과값 하나만 나와야 함
from employees
where department_id is not null
group by department_id);
-- 부서별 사원수를 조회했을 때 사원수가 가장 많은 부서의 아이디와 사원수 조회하기
-- with ~ as 는 쿼리에서 여러번 사용되는 조회결과를 미리 조회해서 메모리에 저장시키고, 테이블처럼 사용할 수 있도록 한다.
with employee_count
as (
select department_id, count(*) cnt
from employees
where department_id is not null
group by department_id
)
select department_id, cnt
from employee_count
where cnt = (select max(cnt)
from employee_count);

5) 상호연관 서브쿼리
- 서브쿼리가 메인쿼리의 컬럼/표현식을 사용한다.
- 상호연관 서브쿼리는 메인쿼리의 모든 행에 대해서 매번 실행된다.
( 일반적인 서브쿼리는 메인쿼리보다 먼저 실행되고,
단 한번만 실행되지만, 상호연관 서브쿼리는 그렇지 않다. )
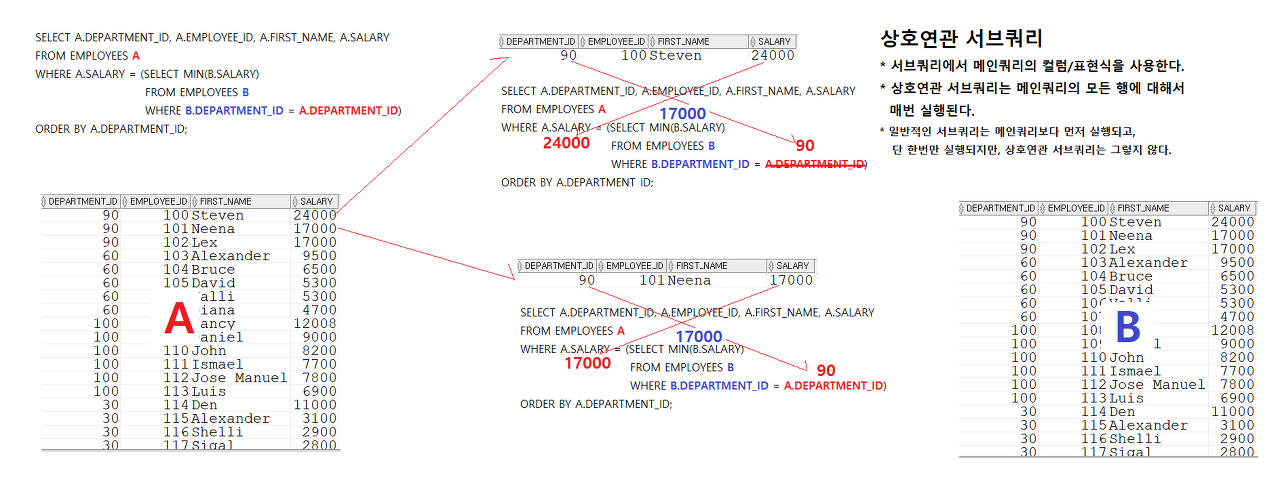
* 부서별 최소급여를 받는 직원 조회하기
- 부서아이디가 일치하는 사원의 급여 중에 최소급여와 메인쿼리의 모든 행의 급여를 비교
employees a 테이블에서 각 행마다 부서아이디를 가져와
먼저 부서아이디가 90일 때, 100번 사원의 급여는 24000원
그러면
이 때의 부서아이디 (90)와
서브쿼리 안의 employees b 테이블의 부서아이디가 일치하는 경우의 최소급여를 조회해
-> 부서아이디 90의 최소급여는 17000
그럼 이 100 사원의 급여(24000)와 부서 90의 최소급여(17000)를 비교
-> 다르면 값에 넣지 않음, 같으면 그 사원의 정보를 조회

-- 부서별 최저급여를 조회했을 때, 각 부서에서 최저급여를 받는 직원의 아이디, 이름, 급여, 부서아이디 조회하기
-- 서브쿼리 안에 바깥 메인쿼리의 컬럼이 들어가있음
-- 서브쿼리가 조회된 행의 개수만큼 실행
select a.employee_id, a.first_name, a.department_id, a.salary
from employees a
where a.salary = (select min(b.salary)
from employees b
where b.department_id = a.department_id)
order by a.department_id;

6) 스칼라 서브쿼리
- 하나의 행에서 하나의 값만 반환하는 서브쿼리다.
- 서브쿼리의 결과가 단일행-단일열 O (1행1열)
- 스칼라 서브쿼리는 select절, insert문의 values에서 사용할 수 있다.
- 스칼라 서브쿼리는 decode 및, case의 조건 및 표현식에서 사용할 수 있다.
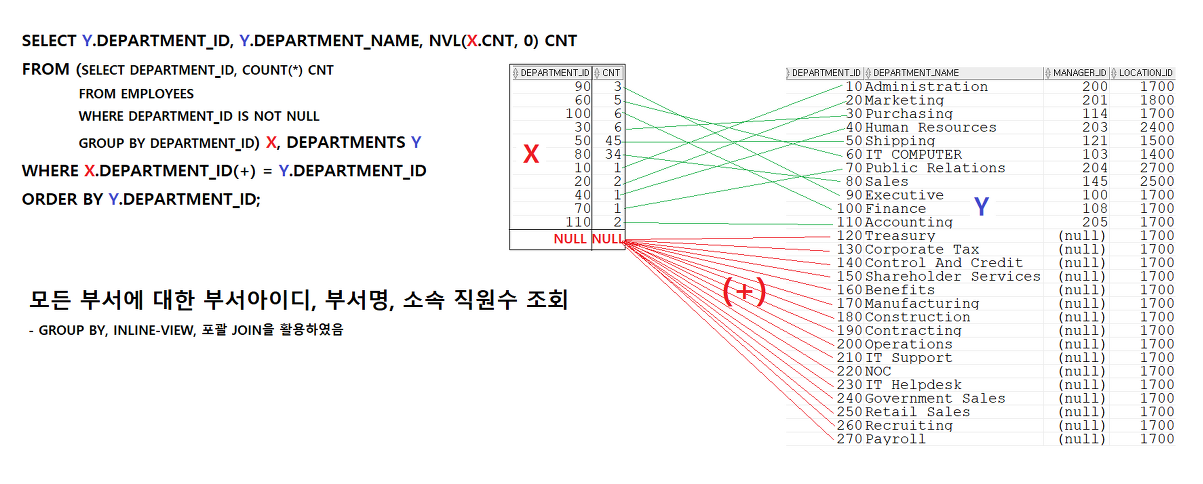
-- 모든 부서의 부서아이디, 이름, 소속사원수 조회하기 (group by, 인라인뷰, 포괄조인 사용)
select y.department_id, y.department_name, nvl(x.cnt, 0) cnt
from (select department_id, count(*) cnt
from employees
where department_id is not null
group by department_id) x, departments y
where x.department_id(+) = y.department_id -- y.department에는 null값이 있으니까 x에 (+) 붙여줌
order by y.department_id;
-- 모든 부서의 부서아이디, 이름, 소속사원수 조회하기 (상호연관 서브쿼리 사용)
-- * select 절에 사용되는 서브쿼리를 특별히 스칼라 서브쿼리라고 한다.
-- * 스칼라 서브쿼리의 실행결과는 반드시 단일행, 단일열이어야 한다.
select a.department_id, a.department_name, (select count(*)
from employees b
where b.department_id = a.department_id) cnt
from departments a
order by a.department_id;
* 각 행마다 (= a.department_id = 10일 때, 20일 때, 30일 때) 상호연관 서브쿼리가 실행되고
b.department_id = a.department_id 일 때 카운트를 함

(+)를 할 때, 꼭 그 값이 null이 아니어도, 값이 연결할데가 없는거는 다 null이랑 연결
--------------------------------------------------------------------------------
-- 퀴즈
--------------------------------------------------------------------------------
--1. 'Neena'와 같은 부서에 근무하는 직원의 아이디, 이름 조회하기
select employee_id, first_name
from employees
where department_id = (select department_id
from employees
where first_name = 'Neena');
--2. 50번 부서에 소속된 직원 중에서 전체 직원의 평균급여보다 급여를 많이 받는 직원의 아이디, 이름, 급여 조회하기
select employee_id, first_name, salary
from employees
where department_id = 50
and salary > (select avg(salary)
from employees);
-- 3. 커미션을 받는 사원 중에서 직종 변경이력이 있는 직원의 직원아이디, 근무했던 직종아이디, 시작일, 종료일을 조회하기
select employee_id, job_id, start_date, end_date
from job_history
where employee_id in (select employee_id
from employees
where commission_pct is not null);
select h.employee_id, h.job_id, h.start_date, h.end_date
from job_history h, employees e
where h.employee_id = e.employee_id
and e.commission_pct is not null;
-- 4. 'Alexander'와 같은 해에 입사한 직원의 아이디, 이름, 입사일을 조회하기
select employee_id, first_name, hire_date
from employees
where to_char(hire_date, 'yyyy') in (select to_char(hire_date, 'yyyy')
from employees
where first_name = 'Alexander');
-- 5. 직종별로 직원수를 조회했을 때 사원수가 가장 많은 직종아이디와 사원수를 조회하기
select job_id, count(*)
from employees
group by job_id
having count(*) = (select max(count(*))
from employees
group by job_id);
-- 6. 직원들이 소속된 부서 소재지의 도시별로 직원수를 조회하기
-- 1) 직원들의 소속 부서의 도시를 조회
-- 2) 도시별로 그룹핑, 카운트
select l.city, count(*)
from employees e, departments d, locations l
where d.location_id = l.location_id
and e.department_id = d.department_id
group by l.city;
-- 7. 가장 많은 사원이 입사한 해에 입사한 사원들의 아이디, 이름, 입사일을 조회하기
-- 1) 가장 많은 사원이 입사한 해
select employee_id, first_name, hire_date
from employees
where to_char(hire_date, 'yyyy') = (select to_char(hire_date, 'yyyy')
from employees
group by to_char(hire_date,'yyyy')
having count(*) in ( select max(count(*))
from employees
group by to_char(hire_date, 'yyyy')));
-- 8. 급여 등급별로 직원수를 조회했을 때 직원수가 10명 이상인 급여 등급과 직원수를 조회하기
select g.salary_grade, count(*)
from employees e, salary_grades g
where e.salary >= g.min_salary and e.salary <= g.max_salary
group by g.salary_grade
having count(*) >= 10;
-- 9. 관리자별로 직원수를 조회했을 때 관리자아이디, 관리자명, 관리하는 직원수를 조회하기
select e.manager_id, m.first_name, count(*)
from employees e, employees m
where e.manager_id = m.employee_id
and e.manager_id is not null
group by e.manager_id, m.first_name;
-- 10. 모든 부서정보에 대해서 부서아이디, 부서명, 관리자명, 소속사원수, 부서 평균급여를 조회하기
select d.department_id, d.department_name, e.first_name, c.cnt, c.avg_salary
from departments d, employees e, (select department_id, count(*) cnt, trunc(avg(salary))avg_salary
from employees
where department_id is not null
group by department_id) c
where d.department_id = c.department_id(+)
and d.manager_id = e.employee_id(+)
order by 1;
-- SQL 주말과제
-- 1. departments 테이블의 모든 행, 모든 열을 조회하기
select *
from departments;
-- 2. departments 테이블의 부서아이디, 부서명을 조회하기
select department_id, department_name
from departments;
-- 3. 직원의 아이디, 이름, 급여, 연봉을 조회하기
-- 연봉은 급여*12다.
select employee_id, first_name, salary, salary*12 annual_salary
from employees;
-- 4. 직원들이 맡고 있는 업종아이디를 중복없이 조회하기
select distinct job_id
from employees;
-- 5. 직원들이 소속된 부서이름을 중복없이 조회하기
select distinct d.department_name
from employees e, departments d
where e.department_id = d.department_id;
select department_name
from departments
where department_id in (select distinct department_id
from employees);
-- 6. 90번 부서에서 근무하고 있는 직원의 아이디, 이름, 직종아이디를 조회하기
select employee_id, first_name, job_id
from employees
where department_id = 90;
-- 7. 급여를 15000달러 이상 받는 직원의 아이디, 이름, 급여를 조회하기
select employee_id, first_name, salary
from employees
where salary >= 15000;
-- 8. 급여를 2500달러 이상 3500달러 이하로 받는 직원의 아이디, 이름, 급여를 조회하기
select employee_id, first_name, salary
from employees
where salary >= 2500 and salary <= 3500;
-- 9. 커미션을 받는 직원아이디와 이름, 급여, 커미션, 연봉을 조회하기
-- 연봉은 급여*12 + 급여*커미션*12다. 커미션 금액은 소수점아래를 버린다.
select employee_id, first_name, salary, trunc(commission_pct, 1), salary*12 + salary*commission_pct*12 annual_salary
from employees
where commission_pct is not null;
-- 10. 관리자 지정되어 있지 않는 직원의 아이디, 이름, 급여, 급여 등급을 조회하기
select employee_id, first_name, salary, salary_grade
from employees, salary_grades
where manager_id is null
and salary >= min_salary and salary <= max_salary;
-- 11. 급여를 10000달러 이상 받고, 직종아이디가 'MAN'으로 끝나는 직원의 아이디, 이름, 직종아이디, 급여를 조회하기
select employee_id, first_name, job_id, salary
from employees
where salary >= 10000
and substr(job_id, 4) = 'MAN'; -- ( = and job_id like '%MAN' )
-- 12. 10,20,40번 부서에 소속된 직원들의 아이디, 이름, 소속부서명을 조회하기
select employee_id, first_name, e.department_id, department_name
from employees e, departments d
where e.department_id in (10, 20, 40)
and e.department_id = d.department_id;
-- 13. 급여를 10000달러 이상 받는 직원들의 부서이름, 급여, 직원아이디, 이름을 조회하기
-- 부서이름에 오름차순, 급여에 대한 내림차순으로 정렬해서 조회하시오.
select d.department_name, salary, employee_id, first_name
from employees e, departments d
where e.salary >= 10000
and e.department_id = d.department_id
order by department_name asc, salary desc;
-- 14. 오늘을 기준으로 직원들의 근무 개월수를 조회해서 직원아이디, 이름, 입사일, 근무개월수를 조회하기
-- 근무개월 수는 소숫점이하는 버리고, 근무개월수를 기준으로 내림차순 정렬하기
select employee_id, first_name, hire_date, trunc(months_between(sysdate, hire_date)) working_months
from employees
order by working_months desc;
-- 15. 오늘을 기준으로 일주일전에 입사한 직원의 아이디, 이름, 입사일을 조회하기
select employee_id, first_name, hire_date
from employees
where hire_date = to_char(sysdate - 7, 'yyyy-mm-dd'); -- 시,분,초 고려
-- 16. 2007년 상반기에 입사한 직원들의 아이디, 이름, 입사일, 직종아이디를 조회하기
-- 입사일을 기준으로 오름차순 정렬하기
select employee_id, first_name, hire_date, job_id
from employees
where hire_date >= '2007-01-01' and hire_date < '2007-07-01'
order by hire_date asc;
-- 17. 모든 직원들의 직원아이디, 이름, 급여, 커미션, 연봉, 급여등급을 조회하고 급여등급에 대한 내림차순으로 조회한다.
-- 연봉은 급여*12 + 급여*커미션*12다. 커미션 금액은 소수점아래를 버린다.
select employee_id,
first_name,
salary,
trunc(nvl(commission_pct, 0), 1) commission,
salary*12 + salary*nvl(commission_pct, 0)*12 annual_salary,
salary_grade
from employees e, salary_grades g
where salary >= g.min_salary and salary <= g.max_salary
order by salary_grade desc;
-- 18. 급여를 15000달러 이상 받으면 10% 급여인상, 10000달러 이상 받으면 15% 급여인상, 그외는 20% 급여가 인상된 값으로 조회하기
-- 직원아이디, 이름, 급여, 인상된 급여를 조회한다. case ~ when 사용
select employee_id, first_name, salary,
case when salary >= 15000 then salary*1.1
when salary >= 10000 then salary*1.15
else salary*1.2
end upgraded_salary
from employees;
-- 19. 부서아이디가 10번인 직원 10% 급여인상, 20번인 직원 15% 급여인상, 그외 20% 급여가 인상된 값을 조회하기
select employee_id, first_name, salary, department_id,
case department_id
when 10 then salary*1.1
when 20 then salary*1.15
else salary*1.2
end upgraded_salary
from employees
order by employee_id;
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY,
DECODE(DEPARTMENT_ID, 10, SALARY + SALARY*0.1,
20, SALARY + SALARY*0.15,
SALARY + SALARY*0.2) AS INCREASED_SALARY
FROM EMPLOYEES;
-- 20. 직원아이디, 직원이름, 직원이 소속된 부서아이디와 부서이름을 조회하기
select employee_id, first_name, e.department_id, d.department_name
from employees e, departments d
where e.department_id = d.department_id(+)
order by employee_id;
-- 21. 부서아이디, 부서이름, 부서담당자아이디, 부서담당자 이름 조회하기
select d.department_id, d.department_name, d.manager_id, e.first_name
from departments d, employees e
where d.manager_id = e.employee_id(+)
order by 1;
-- 22. 직원의 아이디, 직원이름, 소속부서 아이디, 소속부서이름, 소속부서가 위치한 도시 조회하기
select e.employee_id, e.first_name, d.department_id, d.department_name, l.city
from employees e, departments d, locations l
where e.department_id = d.department_id(+)
and d.location_id = l.location_id(+);
-- 23. 부서아이디, 부서이름, 부서담당자아이디, 부서담당자 이름, 그 부서가 위치한 도시 조회하기
select d.department_id, d.department_name, d.manager_id, e.first_name, l.city
from employees e, departments d, locations l
where d.manager_id = e.employee_id(+)
and d.location_id = l.location_id;
-- 24. 직원 아이디, 직원이름, 자신의 매니저 아이디, 매니저 이름 조회하기
select e.employee_id, e.first_name, e.manager_id, m.first_name
from employees e, employees m
where e.manager_id = m.employee_id(+);
-- 25. 전체 직원의 평균급여보다 많은 급여를 받는 직원의 아이디, 이름, 직종아이디, 급여를 조회하기
select employee_id, first_name, job_id, salary
from employees
where salary > (select avg(salary)
from employees);
-- 26. 부서별 급여평균을 조회해서 부서아이디, 평균급여를 표시하기
-- 평균급여는 소숫점이하 부분은 반올림한다.
select department_id, round(avg(salary)) salary
from employees
where department_id is not null
group by department_id
order by department_id;
-- 27. Employees 테이블에서 관리자별 직원수를 계산하고, 그 관리자의 이름과 관리하는 직원수를 조회하기
select e.manager_id, m.first_name, count(*)
from employees e, employees m
where e.manager_id = m.employee_id
group by e.manager_id, m.first_name;
select c.manager_id, e.first_name, c.cnt
from (select manager_id, count(*) cnt
from employees
group by manager_id) c, employees e
where c.manager_id = e.employee_id;
-- 28. employees 테이블에서 직원들의 모든 직종아이디를 중복없이 조회하기
select distinct job_id
from employees;
-- 29. 급여를 12,000달러 이상 받는 직원의 이름과 급여를 조회하기
select first_name, salary
from employees
where salary >= 12000;
-- 30. 직원아이디가 176번 직원의 아이디와 이름 직종을 조회하기
select employee_id, first_name, job_id
from employees
where employee_id = 176;
-- 31. 급여를 12,000달러 이상 15,000달러 이하 받는 직원들의 직원 아이디와 이름과 급여를 조회하기
select employee_id, first_name, salary
from employees
where salary between 12000 and 15000;
-- 32. 2000년 1월 1일부터 2000년 6월 30일 사이에 입사한 직원의 아이디, 이름, 직종아이디, 입사일을 조회하기
select employee_id, first_name, job_id, hire_date
from employees
where hire_date >= '2000-01-01' and hire_date < '2000-07-01';
-- 33. 급여가 5,000달러와 12,000달러 사이이고, 부서아이디가 20 또는 50인 직원의 이름과 급여를 조회하기
select department_id, first_name, salary
from employees
where salary >= 5000 and salary <= 12000
and department_id in (20, 50);
-- 34. 관리자가 없는 직원의 이름과 직종아이디를 조회하기
select first_name, job_id
from employees
where manager_id is null;
-- 35. 커미션을 받는 모든 직원의 이름과 급여, 커미션을 급여 및 커미션의 내림차순으로 정렬해서 조회하기
select first_name, salary, commission_pct
from employees
where commission_pct is not null
order by salary desc, commission_pct desc;
-- 36. 이름의 2번째 글자가 e인 모든 직원의 이름을 조회하기
select first_name
from employees
where instr(first_name, 'e') = 2; -- substr(first_name, 2, 1) = 'e'
-- 37. 직종아이디가 ST_CLERK 또는 SA_REP이고 급여를 2,500달러, 3,500달러, 7,000달러 받는 모든 직원의 이름과 직종아이디, 급여를 조회하기
select first_name, job_id, salary
from employees
where job_id in ('ST_CLERK', 'SA_REP')
and salary in (2500, 3500, 7000);
-- 38. 모든 직원의 이름과 입사일, 근무 개월 수를 계산하여 조회하기, 근무개월 수는 정수로 반올림하고, 근무개월수를 기준으로 오름차순으로 정렬하기
select first_name, hire_date, round(months_between(sysdate, hire_date)) working_months
from employees
order by working_months;
-- 39. 직원의 이름과 커미션을 조회하기, 커미션을 받지 않는 직원은 '없음'으로 표시하기
select first_name, nvl(to_char(commission_pct, '0.99'), '없음')
from employees;
-- 40. 모든 직원의 이름, 부서아이디, 부서이름을 조회하기
select first_name, e.department_id, department_name
from employees e, departments d
where e.department_id = d.department_id(+);
-- 41. 80번부서에 소속된 직원의 이름과 직종아이디, 직종제목, 부서이름을 조회하기
select first_name, e.job_id, job_title, department_name
from employees e, departments d, jobs j
where e.job_id = j.job_id
and e.department_id = d.department_id
and e.department_id = 80;
-- 42. 커미션을 받는 모든 직원의 이름과 직종아이디, 직종제목, 부서이름, 부서소재지 도시명을 조회하기
select first_name, e.job_id, j.job_title, d.department_name, l.city
from employees e, jobs j, departments d, locations l
where commission_pct is not null
and e.job_id = j.job_id
and e.department_id = d.department_id
and d.location_id = l.location_id;
-- 43. 유럽에 소재지를 두고 있는 모든 부서아이디와 부서이름을 조회하기
-- department_location_id = location_country_id = countries_region_id = regions_region_name
select d.department_id, d.department_name
from departments d, locations l, countries c, regions r
where d.location_id = l.location_id
and l.country_id = c.country_id
and c.region_id = r.region_id
and r.region_name = 'Europe';
-- 44. 직원의 이름과 소속부서명, 급여, 급여 등급을 조회하기
select e.first_name, d.department_name, salary, salary_grade
from employees e, departments d, salary_grades g
where e.department_id = d.department_id(+)
and e.salary >= g.min_salary and e.salary <= g.max_salary;
-- 45. 직원의 이름과 소속부서명, 소속부서의 관리자명을 조회하기, 소속부서가 없는 직원은 소속부서명 '없음, 관리자명 '없음'으로 표시하기
select e.first_name emp_name, nvl(d.department_name, '없음'), nvl(m.first_name, '없음') mng_name
from employees e, departments d, employees m
where e.department_id = d.department_id(+)
and d.manager_id = m.employee_id(+); -- 매니저아이디가 없는 부서는 m의 null행과 조인된다.
-- 46. 모든 직원의 급여 최고액, 급여 최저액, 급여 총액, 급여 평균액을 조회하기
select max(salary), min(salary), sum(salary), avg(salary)
from employees;
-- 47. 직종별 급여 최고액, 급여 최저액, 급여 총액, 급여 평균액을 조회하기
select job_id, max(salary), min(salary), sum(salary), avg(salary)
from employees
group by job_id;
-- 48. 각 직종별 직원수를 조회해서 가장 직원수가 많은 직종 3개를 조회하기, 직종아이디와 직원수 표시하기
select job_id, a.cnt
from (select job_id, count(*) cnt
from employees
group by job_id
order by count(*) desc) a
where rownum < 4;
-- 49. 관리자별 직원수를 조회하기, 관리자 이름과 그 관리자가 관리하는 직원수 표시하기
select a.first_name, b.cnt
from employees a, (select manager_id, count(*) cnt
from employees
group by manager_id) b
where a.employee_id = b.manager_id;
-- 50. 모든 부서에 대해 부서이름, 관리자 이름, 소속직원 수, 소속직원들의 평균 급여를 조회하기
select d.department_id, d.department_name, e.first_name mng_name, c.cnt, c.avg_salary
from employees e, departments d, (select department_id, count(*) cnt, trunc(avg(salary)) avg_salary
from employees
group by department_id
order by 1) c
where d.manager_id = e.employee_id(+) --부서의 관리자 이름 필요
and c.department_id = d.department_id --부서명 필요
order by 1;
-- 51. Steven King과 같은 부서에 속한 직원의 이름과 입사일을 조회하기
select first_name, hire_date
from employees
where department_id = (select department_id
from employees
where first_name = 'Steven' and last_name = 'King')
and employee_id != (select employee_id
from employees
where first_name = 'Steven' and last_name = 'King');
-- 52. 소속 부서의 평균급여보다 많은 급여를 받는 직원의 아이디와 직원이름, 급여, 그 부서의 평균 급여를 조회하기
select a.department_id, a.employee_id, a.first_name, a.salary, trunc(b.avg_salary)
from employees a, (select department_id, avg(salary) avg_salary
from employees
group by department_id
order by 1) b
where a.department_id = b.department_id
and salary > b.avg_salary
order by 1;
with dept_avg_salary
as (
select department_id, avg(salary) avg_salary -- 부서별 평균 급여
from employees
where department_id is not null
group by department_id
)
select e.employee_id, e.first_name, e.salary, d.avg_salary
from employees e, dept_avg_salary d
where e.department_id = d.department_id --부서 아이디 동일
and e.salary > d.avg_salary --평균급여보다 급여를 많이 받는
order by e.employee_id asc;
-- 53. Kochhar과 동일한 급여 및 커미션을 받는 모든 직원의 이름과 입사일 급여를 조회하기, 결과에 Kochhar은 포함시키지 않기
select first_name, hire_date, salary
from employees
where (salary, nvl(commission_pct,0)) in (select salary, nvl(commission_pct,0) commission
from employees
where last_name = 'Kochhar')
and last_name != 'Kochhar';
-- 54. 소속 부서에 입사일이 늦지만, 더 많은 급여를 받는 직원의 이름과 소속부서명, 급여를 조회하기 (입사일이 더 늦고 and 더 많은 급여)
-- 1) 소속 부서별로 그룹화 -> 입사일이 가장 늦은 and 급여가 높은
select distinct x.first_name, d.department_name, x.salary
from employees x, employees y, departments d
where x.department_id = y.department_id -- 같은부서
and x.department_id = d.department_id -- 소속부서명을 조회를 위한 d와의 조인 조건
and x.hire_date > y.hire_date -- 입사일이 늦은
and x.salary > y.salary; -- 급여를 많이 받는
--55. 관리자 아이디, 관리자명, 그 관리자가 관리하는 직원수, 그 관리자가 소속된 부서를 조회하기
select x.manager_id, e.first_name, x.cnt, e.department_id, d.department_name
from employees e, (select manager_id, count(*) cnt
from employees
group by manager_id) x, departments d
where x.manager_id = e.employee_id(+)
and e.department_id = d.department_id;