1. 오라클 내장함수
- SQL 작성이 사용할 수 있는 유용한 기능이 제공되는 함수
- DBMS 제품마다 조금씩 차이가 있다.
1-1. 오라클 내장함수의 종류
- 단일행 함수
- 조회된 행마다 하나의 결과를 반환한다.
- 단일행 함수는 중첩해서 사용할 수 있다.
- 종류
- 문자함수 : 문자를 입력값으로 받아서 계산한 결과를 반환
- 숫자함수 : 숫자를 입력값으로 받아서 계산한 결과를 반환
- 날짜함수 : Date 타입의 값에 대한 처리를 수행
- 변환함수 : 데이터의 타입을 변환하는 처리를 수행
- 기타함수 : nvl, case, decode 등의 함수가 있다.
- 다중행 함수(그룹함수)
- 조회된 행을 그룹으로 묶고 그룹당 하나의 결과를 반환한다.
- group by 절을 사용해서 조회된 행을 그룹으로 묶고 다중행 함수로 각 그룹당 하나의 결과(합계, 평균, 분산, 표준편차, 최고값, 최저값) 등을 계산해 낸다.
1-2. 단일함수
1) 문자함수
- length(column or exp) : 텍스트의 길이를 반환한다.
-- length(컬럼명 혹은 표현식) : 문자열의 길이를 반환
select first_name, length(first_name)
from employees
where department_id = 60;
- lower(column or exp) : 소문자로 변환한다.
- upper(column or exp) : 대문자로 변환한다.
-- lower(컬럼명 혹은 표현식), upper(컬럼명 혹은 표현식) : 소문자, 대문자로 변환
select first_name, lower(first_name), upper(first_name)
from employees
where department_id = 60;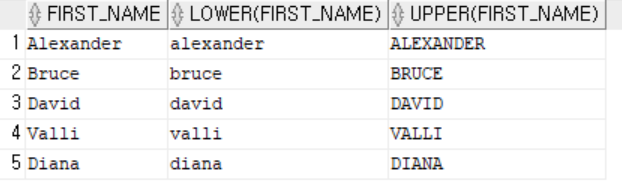
- substr(column or exp, beginIndex) : 텍스트값을 시작위치부터 끝까지 잘라낸다.
- substr(column or exp, beginIndex, length) : 텍스트의 값을 시작위치부터 지정된 길이만큼 잘라낸다.
-- substr(컬렴명 혹은 표현식, 시작위치) : 지정된 시작위치부터 문자열의 끝까지 잘라서 반환
-- substr(컬럼명 혹은 표현식, 시작위치, 길이) : 지정된 시작위치부터 길이만큼 잘라서 반환
select job_id, substr(job_id, 4, 2)
from employees
where salary >= 10000;
- instr(column or exp, 'string') : 텍스트에서 지정된 문자열이 처음으로 등장하는 위치를 반환한다.
-- instr(컬렴명 혹은 표현식, '텍스트') : 지정된 텍스트가 등장하는 위치를 반환
-- instr(컬렴명 혹은 표현식, '텍스트', 검색시작위치) : 지정된 텍스트가 등장하는 위치를 검색시작위치부터 찾아서 반환
select first_name, instr(first_name, 'e')
from employees
where department_id = 60;
select first_name, instr(upper(first_name), 'A') --내장함수 중첩
from employees
where department_id = 60;

- lpad(column or exp, length, 'string') : 텍스트의 길이가 지정된 길이보다 부족하면 지정된 문자를 왼쪽에 채운다.
- rpad(column or exp, length, 'string') : 텍스트의 길이가 지정된 길이보다 부족하면 지정된 문자를 오를쪽에 채운다.
-- lpad(컬렴명 혹은 표현식, 길이, '텍스트') : 지정된 길이보다 짧으면 왼쪽에 텍스트를 채워서 지정된 길이로 맞춘다.
-- rpad(컬럼명 혹은 표현식, 길이, '텍스트') : 지정된 길이보다 짧으면 오른쪽에 텍스트를 채워서 지정된 길이로 맞춘다.
select first_name, lpad(first_name, 15, '#'), rpad(first_name, 15, '#')
from employees
where department_id = 60;

- concat(column or exp, column or exp) : 텍스트 2개를 연결한다.
-- concat(컬럼 혹은 표현식, 컬럼 혹은 표현식) : 두 값을 합쳐서 새로운 텍스트를 반환
select concat(first_name, last_name)
from employees
where department_id = 60;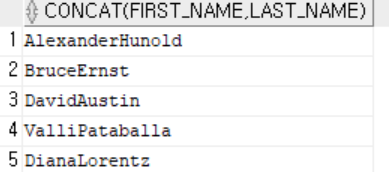
- || (자바의 + 기호)
-- ||는 텍스트를 연결한다
select first_name || ' ' || last_name
from employees
where department_id = 60;
- replace(column or exp, 'search_string', 'replacement_string') : 텍스트에서 검색된 문자를 대체할 문자로 바꾼다.
-- replace(컬럼 혹은 표현식, '텍스트', '대체할 텍스트') : 텍스트에 해당하는 문자를 지정된 텍스트로 대체
select first_name, replace(first_name, 'a', '*')
from employees
where department_id = 60;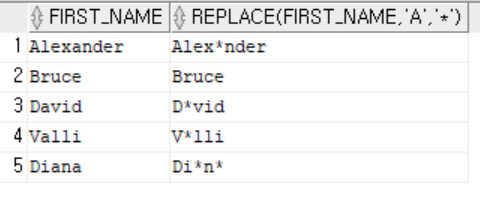
2) 숫자함수
* dual : 1행 1열짜리 테스트용 테이블
- round(column or exp) : 숫자를 소숫점 첫번째 자리에서 반올림한다.
- round(column or exp, n) : 숫자를 지정된 자릿수로 반올림한다.
-- round(컬럼 혹은 표현식) : 소수점 1번째 자리에서 반올림
-- round(컬럼 혹은 표현식, 자리수) : 지정된 자리수로 반올림 (음수도 가능)
select round(123.45), round(1234.5), -- 소수점 1번째 자리에서 반올림
round(123.4567, 3), -- 소수점 3번째자리로 반올림
round(123.4567, 0), -- 1의 자리로 반올림
round(123.4567, -1), -- 10의 자리로 반올림
round(123.4567, -2) -- 100의 자리로 반올림
from dual;
- trunc(column or exp) : 숫자의 소수점부분을 버린다.
- trunc(column or exp, n) : 숫자를 지정된 자릿수만큼 남기고 버린다.
-- trunc(컬럼 혹은 표현식) : 소수점부분을 전부 버린다.
-- trunc(컬럼 혹은 표현식, 자리수) : 지정된 자리수만큼 남기고 전부 버린다.
select trunc(1234.1), trunc(1234.5), --소수점 이하를 전부 버린다.
trunc(1234.1, 0), --1의 자리 이하를 전부 버린다.
trunc(1234.1, -2), --100의 자리 이하를 전부 버린다.(0으로 한다.)
trunc(1234.1, -3) --1000의 자리 이하를 전부 버린다.(0으로 한다.)
from dual;
select first_name, salary, commission_pct, salary*commission_pct, trunc(salary*commission_pct, -2)
from employees
where commission_pct is not null;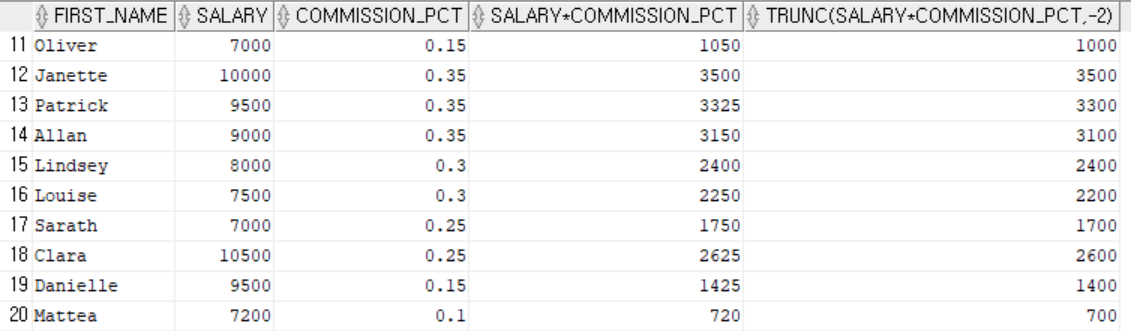
- mod(m, n) : m을 n으로 나눈 나머지값을 반환한다.
-- mod(컬럼 혹은 표현식, 숫자) : 나머지 값을 반환
select 5/2, -- 나누기: 2.5
mod(5,2) -- 나머지: 1
from dual;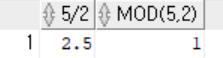
3) 날짜함수
- sysdate : 시스템의 현재날짜와 시간을 반환한다.
-- sysdate : 시스템의 현재 날짜와 시간정보가 포함된 날짜정보를 반환 (입력값이 없는 함수는 ()를 생략)
select sysdate
from dual;
- months_between(날짜, 날짜) : 두 날짜사이의 월수를 반환한다.
-- months_between(날짜, 날짜) : 두 날짜 사이의 개월수 반환
select first_name, hire_date, trunc(months_between(sysdate, hire_date)) MONTHS
from employees
where department_id = 60;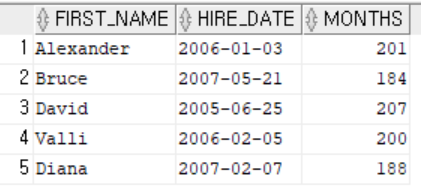
- add_months(날짜, 숫자) : 날짜에서 숫자만큼 개월수를 증감시킨 값을 반환한다.
-- add_months(날짜, 개월수) : 지정된 날짜에서 개월수만큼 경과한 날짜를 반환
select add_months(sysdate, 1), add_months(sysdate, 6),
add_months(sysdate, -1), add_months(sysdate, -6)
from dual;
- round(날짜) : 날짜를 반올림한다. 정오가 지나면 하루가 증가된다.
- trunc(날짜) : 지정된 날짜에서 시간정보를 전부 0으로 바꾼 값을 반환한다.
-- round(날짜) : 날짜를 반올림. 정오가 넘어가면 날짜가 하루 증가된 값 반환 (시분초값은 전부 0)
-- trunc(날짜) : 날짜에서 시분초값을 전부 버린다.
select sysdate, -- 2022-10-18 11:07:40 -- 2022-10-18 14:07:40
round(sysdate), -- 2022-10-18 00:00:00 -- 2022-10-19 00:00:00
trunc(sysdate) -- 2022-10-18 00:00:00 -- 2022-10-18 00:00:00
from dual;
- 날짜연산
- 날짜 + 숫자 : 지정된 날짜에서 숫자만큼 경과된 날짜를 반환한다.
- 날짜 - 숫자 : 지정된 날짜에서 숫자만큼 이전 날짜를를 반환한다.
- 날짜 - 날짜 : 두 날짜사이의 날짜수를 반환한다.
-- 날짜 + 정수 : 지정된 날짜에서 지정된 정수만큼 경과된 날짜를 반환
-- 날짜 - 정수 : 지정된 날짜에서 지정된 정수만큼 이전의 날짜 반환
-- 날짜 + 정수/ 24 : 지정된 날짜에서 지정된 정수시간만큼 경과된 날짜 반환
-- 날짜 - 정수/ 24 : 지정된 날짜에서 지정된 정수시간만큼 이전의 날짜 반환
-- 날짜 - 날짜 : 두 날짜 사이의 경과된 일수 반환
select sysdate + 3, -- 지금을 기준으로 3일 후
sysdate - 3, -- 지금을 기준으로 3일 전
sysdate + 3/24, -- 지금을 기준으로 3시간 후
sysdate - 3/24 -- 지금을 기준으로 3시간 전
from dual;
-- 지금(2022/10/18 11:24:58)을 기준으로 최근 7일 동안의 주문내역 조회하기
-- 7일 전 ~ 오늘 0시
select *
from orders
where order_date >= trunc(sysdate - 7) and order_date < trunc(sysdate);
4) 데이터타입 변환
- 묵시적 타입 변환 : 쿼리 실행과정에서 자동으로 데이터타입이 변환됨
- 문자를 숫자로 (문자가 숫자로만 구성되어 있을 때)
- 문자를 날짜로 (문자가 날짜표기 형식의 문자일 때)
-- 묵시적 타입변환 : 컬럼의 데이터타입을 참조해서 자동으로 데이터타입을 변환
select *
from employees
where employee_id ='100'; -- employee_id컬럼의 데이터타입이 number 타입이기 때문에 '100'이 100으로 타입 변환
select *
from employees
where hire_date = '2007-01-14'; -- hire_date 컬럼의 데이터타입이 date 타입이기 때문에 '2007-01-14'가 date타입으로 변환된다.
select *
from employees
where hire_date = '2007/01/14'; -- hire_date 컬럼의 데이터타입이 date 타입이기 때문에 '2008/01/14'가 date타입으로 변환
-- 2007년에 입사한 사원 조회하기
select *
from employees
where hire_date >= '2007/01/01' and hire_date < '2008/01/01'
order by hire_date;
-- 2007년에 입사한 사원 조회하기
SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
WHERE HIRE_DATE >= '2007/01/01' AND HIRE_DATE <= '2007/12/31 23:59:59'
ORDER BY HIRE_DATE;
- 명시적 타입 변환
- to_char(숫자, '포맷형식'), to_char(날짜, '포맷형식')
- 숫자와 날짜를 지정된 포맷형식의 문자로 변환한다.
- 비추천
-- to_char(숫자, '포맷형식') : 숫자를 지정된 포맷형식의 텍스트로 변환
-- sql에서 숫자값을 ,가 포함된 텍스트로 변환하는 작업은 비추천
select employee_id, first_name, to_char(salary, '99,999')
from employees
where department_id = 60;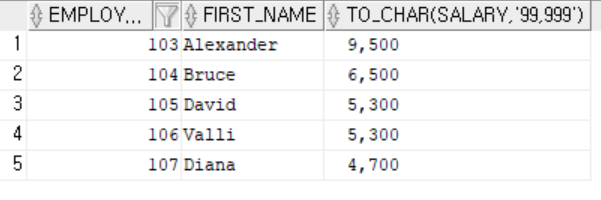
-- to_char(날짜, '포맷형식') : 날짜를 지정된 포맷형식의 텍스트로 변환
select
to_char(sysdate, 'YYYY') YEAR, -- date타입을 텍스트로 변환. sysdate -> '2022'
to_char(sysdate, 'MM/DD') DAY, -- date타입을 텍스트로 변환. sysdate -> '10/18'
-- to_char(sysdate, 'M/D') -- D나 M을 한번만 적으면 오류
to_char(sysdate, 'am'), -- date타입을 텍스트로 변환. sysdate -> '오후'
to_char(sysdate, 'HH:MI:SS'), -- date타입을 텍스트로 변환. sysdate -> '12:24:11'
to_char(sysdate, 'HH24:MI:SS') -- date타입을 텍스트로 변환. sysdate -> '12:24:11'
from dual;
-- 연도 상관없이 이번달 입사자 조회하기 (이번달 생일)
select employee_id, first_name, hire_date
from employees
where to_char(hire_date, 'MM') = to_char(sysdate, 'MM');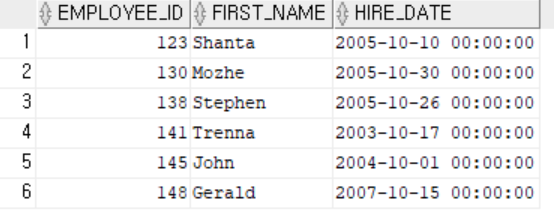
- to_number('특정패턴으로 구성된 숫자형식의 문자', '패턴')
- ,가 포함된 문자열을 숫자로 변환한다.
- 패턴 문자
- 9 숫자를 나타낸다
- 0 숫자를 나타낸다.
- $ 달러 기호를 나타낸다.
- . 소숫점을 나타낸다.
- , 자릿수를 나타낸다.
-- to_number('텍스트', '패턴') : 지정된 패턴과 일치하는 텍스트를 숫자로 변환
-- 텍스트에 숫자가 아닌 텍스트가 포함되어 있지 않으면 패턴을 지정하지 않아도 된다.
select to_number('1234') + to_number('1234') -- 명시적 형변환
from dual;
-- 텍스트에 숫자가 아닌 텍스트가 포함되어 있지 않으면 명시적 형변환이 필요없다.
select '1234' + '1234' -- 묵시적 형변환
from dual;
-- 텍스트에 숫자가 아닌 텍스트가 포함되어 있는 경우 패턴을 지정해야 한다.
select to_number('1,234', '9,999') + to_number('1,234', '9,999') -- 명시적 형변환
from dual;
select '1,234' + '1,234' -- 묵시적 형변환 오류
from dual;
- to_date('특정 패턴으로 작성된 날짜형식의 문자', '패턴')
- 문자열을 날짜로 변환한다.
-- to_date('텍스트', '패턴') : 지정된 패턴과 일치하는 텍스트를 날짜로 변환
select trunc(sysdate) - to_date('1996/01/22', 'yyyy/mm/dd')
from dual;
5) 기타 함수
- nvl(null값이 예상되는 컬럼, 대체할 값)
- nvl은 null값을 지정된 대체값으로 변환한다.
- 컬럼의 값이 null이 아닌 경우에는 그 컬럼의 원래값이 반환된다.
- nvl에서는 첫번째 항목과 두번째 항목의 데이터 타입이 동일해야 한다.
- 주로 null값을 포함하고 있는 컬럼이 연산식에 포함되어 있을 때 사용한다.
-- nvl(컬럼 혹은 표현식, 대체할 값) : 지정된 컬럼 혹은 표현식의 값이 null이면 대체할 값을 반환
-- : 원래 값과 대체할 값의 타입이 같은 타입이어야 한다.
-- 급여 실수령액 계산하기
-- 실수령액 = salary + salary*commission_pct
-- * commission_pct가 null인 경우 실수령액이 null값으로 계산된다.
-- * nvl() 함수를 사용해서 commission_pct가 null일 때, 0을 반환하도록 한다.
select employee_id, first_name, salary, commission_pct,
nvl(commission_pct, 0), -- commission_pct값이 null이면 0을 반환하고, 아니면 commission_pct값을 반환
salary + salary*nvl(commission_pct,0) real_salary
from employees
where salary >= 10000;
-- nvl2(컬럼 혹은 표현식, null이 아닐 때 대체할 값, null일 때 대체할 값)
-- * 대체할 값들끼리는 데이터타입이 동일한 값이어야 한다.
select employee_id, first_name, nvl2(commission_pct, '커미션 받음', '커미션 안받음')
from employees
where salary >= 10000;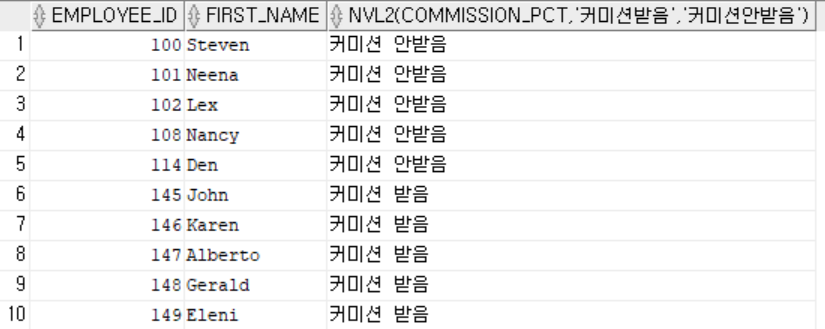
- case ~ when ~ then ~ end
- 제시된 조건에 따라서 다른 조회결과를 제공받을 수 있다.
- java의 switch나 if ~ else if ~ else과 유사한다.
* if ~ else if ~ else 형식으로 사용하기
case
when 조건식1 then 표현식1 -- 조건식1이 true이면 표현식1이 최종결과
when 조건식2 then 표현식2 -- 조건식2가 true이면 표현식2이 최종결과
when 조건식3 then 표현식3 -- 조건식3이 true이면 표현식3이 최종결과
else 표현식4 -- 위 조건식이 모두 false이면 표현식4가 최종결과
end
* switch문 형식으로 사용하기
case 컬럼 혹은 표현식
when 값1 then 표현식 -- 컬럼 혹은 표현식의 값이 값1과 일치하면 표현식1이 최종결과
when 값2 then 표현식 -- 컬럼 혹은 표현식의 값이 값2과 일치하면 표현식2이 최종결과
when 값3 then 표현식 -- 컬럼 혹은 표현식의 값이 값3과 일치하면 표현식3이 최종결과
else 표현식 -- 컬럼 혹은 표현식의 값과 모두 일치하지 않으면 표현식4가 최종결과
end
-- 직원아이디, 이름, 급여, 급여등급 조회하기
-- 급여등급 : A-20000이상, B-15000이상, C-10000이상, D-5000이상, E-2500이상, F-1000이상
select employee_id, first_name, salary,
case
when salary >= 20000 then 'A'
when salary >= 15000 then 'B'
when salary >= 10000 then 'C'
when salary >= 5000 then 'D'
when salary >= 2500 then 'E'
when salary >= 1000 then 'F'
else 'G'
end as employee_grade
from employees
order by employee_grade;
-- 직원아이디, 이름, 급여, 보너스 조회하기
-- 보너스는 10000불 이상은 급여의 10%, 5000불 이상은 20%, 그외는 급여의 30%를 보너스로 지급한다.
select employee_id, first_name, salary,
case
when salary >= 10000 then salary*0.1
when salary >= 5000 then salary*0.2
else salary*0.3
end as bonus
from employees
order by employee_id asc;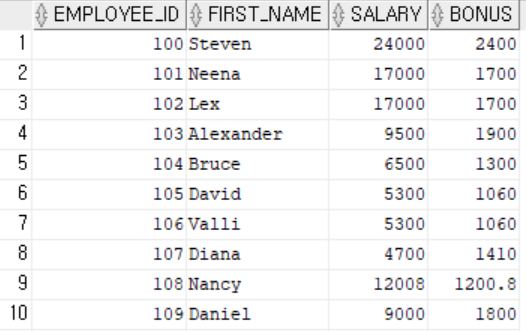
-- 100번 부서에 근무하는 직원의 직원아이디, 이름, 급여, 보너스 조회하기
-- 보너스는 직종에 따라서 지급되며, FI_MGR: 10%, FI_ACCOUNT: 20%를 지급한다.
select employee_id, first_name, job_id, salary,
case job_id
when 'FI_MGR' then salary*0.1
when 'FI_ACCOUNT' then salary*0.2
end as bonus
from employees
where department_id = 100;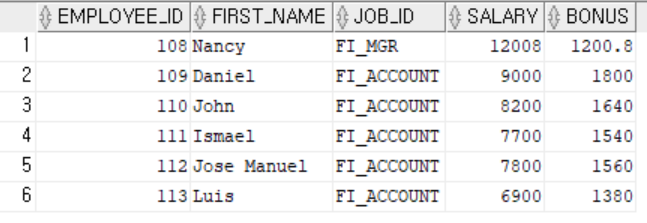
- decode(컬럼, 값, 반환값, 값 반환갑, ...)
- 제시된 조건에 따라서 다른 조회결과를 제공받을 수 있다.
decode(컬럼 혹은 표현식, 값1, 표현식1, --컬럼 혹은 표현식의 값이 값1과 일치하면 표현식1이 최종결과
값2, 표현식2, --컬럼 혹은 표현식의 값이 값1과 일치하면 표현식2가 최종결과
값3, 표현식3) --컬럼 혹은 표현식의 값이 값1과 일치하면 표현식3이 최종결과
decode(컬럼 혹은 표현식, 값1, 표현식1, --컬럼 혹은 표현식의 값이 값1과 일치하면 표현식1이 최종결과
값2, 표현식2, --컬럼 혹은 표현식의 값이 값1과 일치하면 표현식2가 최종결과
값3, 표현식, --컬럼 혹은 표현식의 값이 값1과 일치하면 표현식3이 최종결과
표현식4) --위의 조건식과 모두 일치하지 않으면 표현식4가 최종결과
-- 부서별로 팀나누기
-- A팀(10, 20, 30, 40번 부서), B팀(50, 60번 부서), C팀(70, 80번 부서), D팀(그 외 부서)으로 직원들의 팀 나누기
select employee_id, first_name, department_id,
decode(department_id, 10, 'A팀',
20, 'A팀',
30, 'A팀',
40, 'A팀',
50, 'B팀',
60, 'B팀',
70, 'C팀',
80, 'C팀',
'D팀') TEAM
from employees
order by team asc, department_id asc;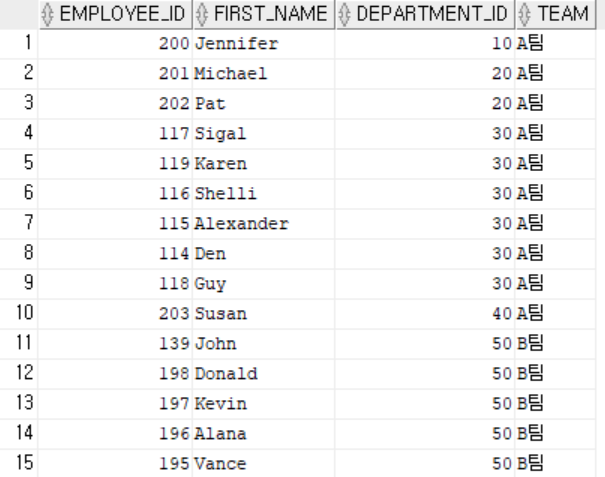
2. 오라클의 데이터타입
- VARCHAR2(size)
- 가변길이 문자 데이터, 최대값: 4000
- size범위내에서 실제 데이터의 크기만큼만 저장공간을 사용한다.
- 예) 이름, 주소, 과목명, 상품명, 뉴스제목
- CHAR(size)
- 고정길이 문자 데이터, 최대값: 2000
- size크기만큼의 저장공간을 무조건 사용한다.
- 예) 주민번호, 학번, 수강과목코드
- LONG
- 가변길이 대용량 문자 데이터, 최대값: 2GB
- 현재는 잘 사용되지 않음
- 테이블당 하나밖에 사용할 수 없다.
- 제약조건을 정의할 수 없다.
- order by나 group by에 포함시킬 수 없다.
- CLOB
- 가변길이 대용량 문자 데이터(Character Large OBject), 최대값: 4GB
- 예) 블로그의 본문, 신문기사, 논문
- NUMBER(p, s)
- 가변길이 숫자 데이터
- p:십진수의 총 갯수, s:소숫점이하 자릿수
- DATE
- 날짜 및 시간 데이터
- 예) 입사일, 가입일, 주문날짜, 이체날짜, 신청날짜 ...
- TIMESTAMP
- 날짜 및 시간 데이터, 소수점 이하 초까지 포함한다.
- BLOB
- 가변길이 대용량 이진 데이터(Binary Large OBject), 최대값: 4GB
- 예) 그림, 영상, 게임파일
※ 퀴즈
--------------------------------------------------------------------------------
-- 퀴즈
--------------------------------------------------------------------------------
-- employees 테이블에서 10, 20, 30번 부서에 소속된 직원의 아이디, 이름, 부서아이디 조회하기
select employee_id, first_name, department_id
from employees
where department_id in (10, 20, 30);
-- employees 테이블에서 80번 부서에 소속된 직원 중에서 커미션을 0.3이상 받는 직원의 아이디, 이름, 급여, 커미션, 실수령액 조회하기
-- 실수령액 = 급여 + 급여*커미션
select employee_id, first_name, salary, commission_pct, salary + salary*commission_pct
from employees
where department_id=80 and commission_pct >= 0.3;
-- employees 테이블에서 소속된 부서가 없는 직원의 아이디, 이름 조회
select employee_id, first_name
from employees
where department_id is null;
-- EMPLOYEES 테이블에서 2007년에 입사한 직원들의 아이디, 이름, 입사일을 조회하기
select employee_id, first_name, hire_date
from employees
where hire_date >= '2007/01/01' and hire_date < '2008/01/01'
order by hire_date asc;
-- EMPLOYEES 테이블에서 2007년에 입사한 직원 중에서 커미션을 받는 직원들의 아이디, 이름, 입사일, 급여, 커미션을 조회하기
select employee_id, first_name, hire_date, salary, commission_pct
from employees
where hire_date >= '2007/01/01' and hire_date < '2008/01/01' and commission_pct is not null;
-- EMPLOYEES 테이블에서 50, 80번 부서에 소속된 직원 중에서 이름(FIRST_NAME)에 'A' 혹은 'a'가 포함된 직원의 아이디, 이름, 부서아이디를 조회하기
select employee_id, first_name, department_id
from employees
where department_id in (50, 80) and instr(upper(first_name),'A')>0 ;
-- EMPLOYEES 테이블에서 입사일이 년도와 상관없이 저번달에 입사한 직원의 아이디, 이름, 입사일을 조회하기
select employee_id, first_name, hire_date
from employees
where to_char(hire_date, 'MM') = to_char(add_months(sysdate,-1), 'MM');
-- employees 테이블에서 오늘을 기준으로 저번달에 입사한 직원의 아이디, 이름, 입사일 조회하기
select to_date(to_char(add_months(sysdate,-1),'yyyymm') || '01'),
add_months(to_date(to_char(add_months(sysdate,-1),'yyyymm') || '01'),1)
from dual;
-- EMPLOYEES 테이블에서 2006년도 상반기(1월~ 6월)에 입사한 직원들의 아이디, 이름, 입사일, 급여, 연봉을 조회하기
-- 연봉 = 급여*12 + 급여*커미션*12 다.
select employee_id, first_name, hire_date, salary,
salary*12 + salary*nvl(commission_pct,0)*12 annual_salary
from employees
where hire_date >= '2006/01/01' and hire_date < '2006/07/01';
-- EMPLOYEES 테이블에서 직원의 이름과 급여를 조회하기
-- 급여에 대해서 '#'으로 표시한다. '#'하나는 1000불에 해당한다.
-- 출력예시
-- 홍길동 2000 ##
-- 김유신 4300 ####
-- 강감찬 6500 ######
select first_name, salary, lpad('#', trunc(salary/1000), '#')
from employees;
-- EMPLOYEES 테이블에서 모든 행의 직원아이디, 이름, 급여, 커미션을 조회하기
-- 단, 커미션이 NULL이면, '없음'으로 출력하기
select employee_id, first_name, salary, nvl(to_char(commission_pct, '0.99'),'없음')
from employees;
'수업내용 > SQL' 카테고리의 다른 글
| [2022.10.20. 목] 오라클 내장함수 - 다중행함수 (0) | 2022.10.20 |
|---|---|
| [2022.10.19.수] 조인 (0) | 2022.10.19 |
| [2022.10.17.월] JDBC (0) | 2022.10.17 |
| [2022.10.14.금] DML (데이터 조회, 정렬, 추가, 변경, 삭제) (0) | 2022.10.14 |
| [2022.10.13.목] 데이터베이스 (0) | 2022.10.13 |